
最近摸了一些 CJK 相關的字碼問題,也不能說多有研究,但算是小心得可以分享,又可以順便做筆記,於是自然就成了本週長知識的題目。
什麼是 CJK
從維基百科的條目上截取的簡述如下:
中日韓統一表意文字(英語:CJK Unified Ideographs),也稱統一漢字(英語:Unihan),目的是要把分別來自中文、日文、韓文、越南文、壯文中,起源相同、本義相同、形狀一樣或稍異的表意文字,賦予其在ISO 10646及萬國碼標準中相同編碼。
所謂「起源相同、本義相同、形狀一樣或稍異的表意文字」,主要為漢字,包括繁體字、簡體字、日本漢字(漢字/かんじ)、韓國漢字(漢字/한자)、越南的喃字(?喃/Chữ Nôm)與儒字(?儒/Chữ Nho)、方塊壯字。
簡單來講基本上就是把所有「看起來像是中文字」的字都合併進來,希望能夠對這些漢字做統一的處理。
可以簡單的看一點統一的例子,下圖取自維基百科
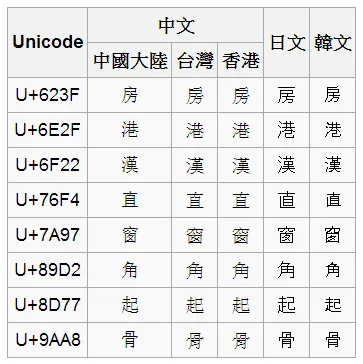
CJK 的字碼資料
基本上所有的字碼資料都收錄在 Unicode 的網站上,完整列表在 http://www.unicode.org/charts/。
進去之後找到 CJK 相關的欄目,再點開看內容的 PDF。
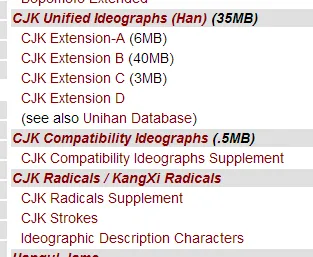
內容的 PDF 裡面有列出涵蓋字碼對應的顯示。
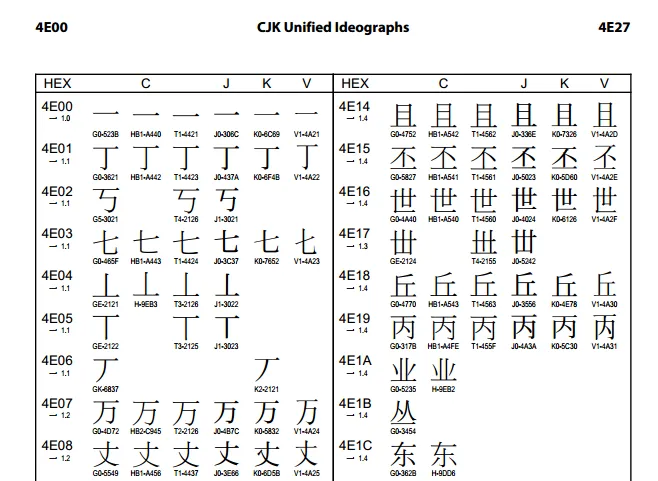
如果想要看整份 PDF 包含的字碼範圍,可以移至第一頁最上方。

CJK 的標點符號
其實符號跟標點符號在 Unicode 列表下面有一整區,可以輕易的在這邊找到 CJK 的標點符號。
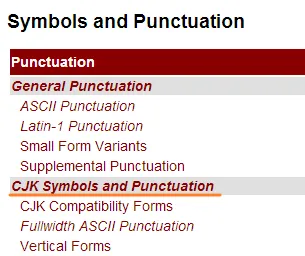
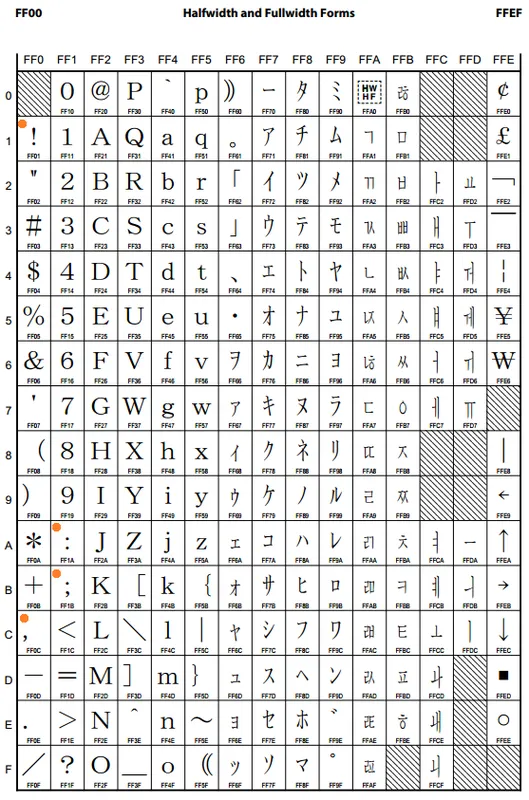
不過點開查看後會發現,中文裡常用的 ,, :, ;, ! 等並不在裡面。
實際上它們被規類在下圖所示的項目裡,裡面除了全形標點符號外還有半形的日文字。
如何查詢字碼在哪份文件(不限 CJK)
同一個網頁上還提供了一個相當方便的功能,可以讓你用 hex code 來查詢某個字碼在哪份文件裡。
我們可以透過簡單的 JavaScript 取得任意字元(或符號)的 hex code。
function hexCode(char) {
return char.charCodeAt(0).toString(16);
}
hexCode('?'); // "ff1f"
hexCode('の'); // "306e"
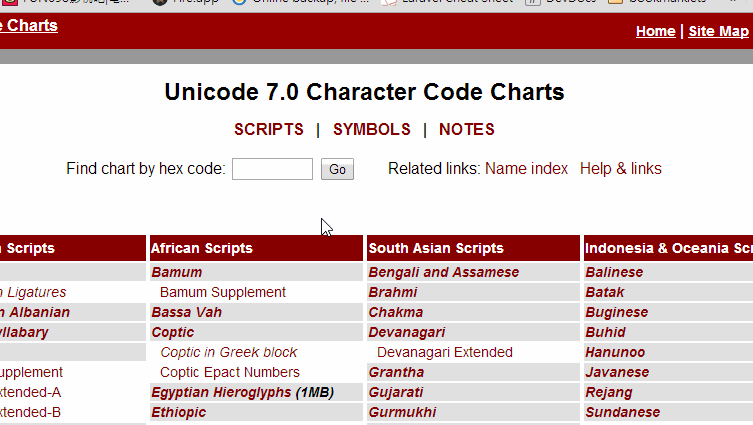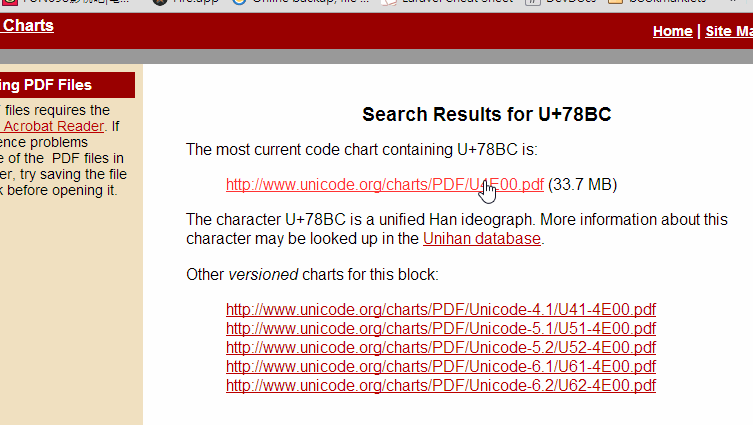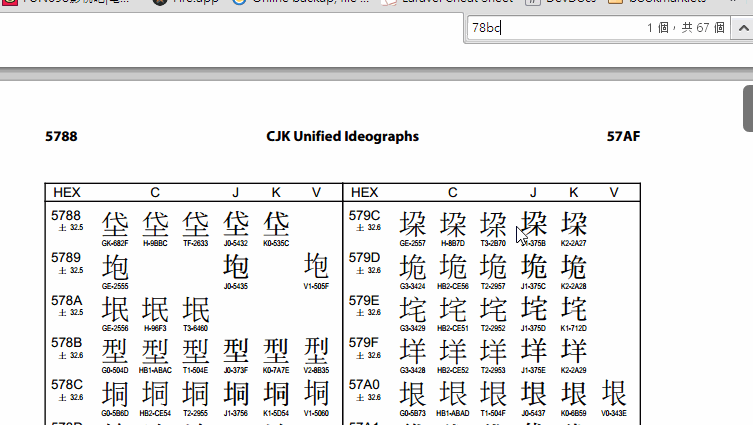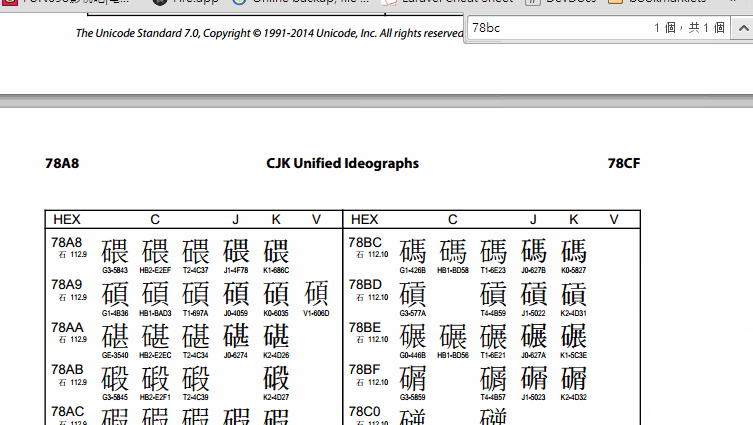
hexCode('碼'); // "78bc"
將得到的 hex code 字碼輸入上方的搜尋框中即可尋找所在的文件,下面是動畫演示。
另外這個週末
我最近發現把一些舊 code 換成 CoffeeScript 之後踩到了小地雷,所以有更新了之前 A Cup of CoffeeScript 裡的 style guide 部分。
新增了兩項:
- 判斷式內的 function call 寫法
- 使用
and,or,is,isnt取代&&,||,==/===,!=/!==
有興趣的話歡迎去逛逛喔!